
Какая информация содержится в локальной таблице дескрипторов

Сегментная организация памяти в защищенном режиме
В основе сегментной модели памяти лежит разделение ее на независимые адресные пространства переменной длины – сегменты. Для программы адресное пространство разделено на блоки смежных адресов, называемых сегментами, а программа может обращаться только к данным, находящимся в этих сегментах. Внутри сегментов применяется линейная адресация, то есть программа может обращаться к байту 0, байту 1 и т. д. Такая адресация осуществляется относительно начала сегмента, и физический адрес, ассоциируемый, например, с программным адресом 0, по существу, скрыт от программиста. Этот подход к управлению памятью опирается на тот факт, что программы обычно логически разделяются на области (сегменты) кода, данных и стека. При этом упрощается изоляция программ друг от друга в мультипрограммном режиме работы. Каждый сегмент имеет свое целевое назначение. Каждая задача имеет непосредственный доступ к трем основным сегментам: кода, данных и стека, определяемых сегментными регистрами CS, DS SS соответственно, и к трем дополнительным сегментам данных, определяемых сегментными регистрами ES, FS, GS. Описания этих сегментов содержатся в их дескрипторах. Любая программа, независимо от уровня ее привилегий, не может обращаться к сегменту до тех пор, пока он не описан с помощью дескриптора, а сам дескриптор не помещен в таблицу дескрипторов.
Дескрипторы хранятся либо в глобальной таблице дескрипторов (Global Descriptor Table – GDT), либо в локальных таблицах дескрипторов (Local Descriptor Table – LDT). В GDT содержатся дескрипторы сегментов, которые доступны всем активным задачам, имеющимся в системе на данный момент. GDT может содержать любые дескрипторы сегментов, за исключением дескрипторов прерываний и ловушек. Обычно GDT включает дескрипторы сегментов кодов и данных операционной системы, сегментов состояния задач и дескрипторы сегментов, содержащих локальные таблицы дескрипторов. Микропроцессорная система имеет единственную глобальную таблицу дескрипторов.
Локальная таблица дескрипторов LDT используется для хранения дескрипторов, доступных только данной задаче. Их количество определяется количеством активных задач в системе.
С точки зрения расположения в памяти, локальные таблицы дескрипторов представляют собой обычные сегменты. Они могут накладываться друг на друга, частично пересекаться. Это приводит к тому, что отдельные сегменты, описанные дескрипторами в своих LDT, могут разделяться несколькими задачами (рис. 3.8).

Рис.
3.8.
Описание сегментов в таблицах дескрипторов
Для нахождения дескриптора в таблице дескрипторов используется селектор, который содержится в одном из сегментных регистров. Селектор представляет собой 16-разрядое слово, которое разбито на 3 поля (рис. 3.9):
- TI ( Table Indicator – индикатор таблицы ) показывает, к какой таблице идет обращение: TI = 0 – дескриптор находится в глобальной таблице дескрипторов GDT, TI = 1 – в локальной таблице LDT;
- Index: поле индекса – номер дескриптора в соответствующей таблице дескрипторов;
- RPL ( Request privilege level – уровень привилегий запроса ). При обращении сравнивается с полем DPL в байте доступа дескриптора.
Обращение разрешается, если уровень привилегий запроса не ниже, чем уровень привилегий дескриптора.

Рис.
3.9.
Формат селектора
Максимальное количество дескрипторов, находящихся в таблице дескрипторов, определяется длиной поля Index селектора и равно 213. Так как каждый дескриптор имеет длину 8 байт, максимальный объем любой таблицы дескрипторов составляет 216байт. Каждая из таблиц дескрипторов имеет регистр ( GDTR для глобальной таблицы и LDTR для локальной), определяющий ее положение в памяти. Регистр GDTR содержит 48 разрядов, из которых 32 задают базовый адрес глобальной таблицы дескрипторов, а 16 указывают ее объем в байтах (границу таблицы). Для определения положения дескриптора относительно начала таблицы его номер (поле Index селектора) умножается на 8, то есть реально сдвигается на три разряда влево, так как длина дескриптора составляет 8 байт. Если селектор обращается к дескриптору, содержащемуся в таблице GDT (при TI = 0 в селекторе), то полученное смещение сравнивается с хранящейся в GDTR границей таблицы. Если нарушения границы нет, то смещение прибавляется к содержащемуся в GDTR базовому адресу, в результате чего образуется физический адрес выбираемого дескриптора (рис. 3.10).
Нулевой дескриптор в GDT является пустым, не используемым. Селектор с нулевым значением разрядов 2….15 называется нуль-индикатором. Он обеспечивает обращение к нулевому дескриптору GDT. Так как этот дескриптор не используется, то при обращении к нему происходит прерывание. Одно из возможных применений пустых селекторов заключается в следующем. Перед инициированием задачи операционная система может загрузить в регистры DS и ES пустые селекторы. Если в последующем не инициализировать эти регистры, то адресация памяти через них вызовет особый случай (прерывание). Загрузка в LDTR пустого селектора, для которого поле Index = 0, допустима. Такая операция сообщает процессору о том, что в задаче не будет использоваться локальная дескрипторная таблица. Это характерно для небольших однопользовательских систем.
Для обращения к локальной таблице дескрипторов предназначен 16-разрядный регистр LDTR. Он содержит селектор, определяющий размещениев GDT дескриптора используемой локальной таблицы дескрипторов.

Рис.
3.10.
Получение дескриптора, находящегося в глобальной таблице дескрипторов GDT
Такая структура упрощает работу с таблицами LDT. Благодаря описанию LDT с помощью селектора эти таблицы превращаются в обычные сегменты памяти и, в частности, могут размещаться в любых областях памяти, участвовать в свопинге и т. п. Внутри процессора с регистром LDTR ассоциируется так называемый “теневой регистр”, в котором и хранится дескриптор LDT текущей задачи. Это ускоряет в последующем обращение к локальной таблице дескрипторов текущей задачи. При переключении с одной задачи на другую для замены используемой LDT достаточно загрузить в регистр LDTR селектор новой LDT, а процессор уже автоматически загрузит в теневой регистр дескриптор новой LDT при первом обращении к нему.
Если в селекторе индикатор таблицы TI = 1, то дескриптор сегмента выбирается из локальной таблицы дескрипторов. Процесс определения адреса сегмента в этом случае представлен на рис. 3.11.
Он более сложен по сравнению с получением дескриптора из глобальной таблицы дескрипторов и проходит следующие этапы:
- Анализируем, к какой из двух возможных таблиц дескрипторов идет обращение. Если в селекторе TI = 1, то обращение идет к локальной таблице дескрипторов.
- Находим дескриптор локальной таблицы дескрипторов в глобальной таблице дескрипторов.
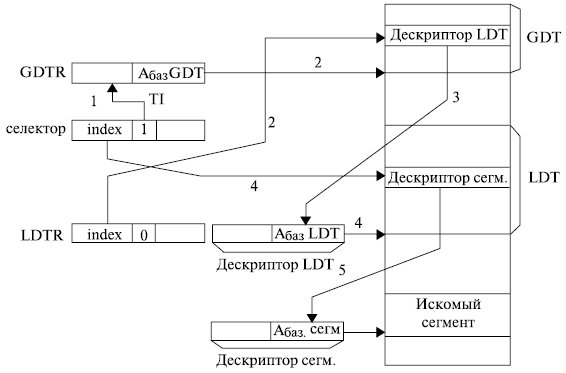
Рис.
3.11.
Получение дескриптора, находящегося в локальной таблице дескрипторов LDT - Считываем дескриптор LDT в “теневой” регистр регистра LDTR микропроцессора. После считывания дескриптора в “теневой” регистр дальнейшее обращение к сегменту аналогично обращению к GDT, где вместо GDT R используются поля базового адреса и предела из дескриптора LDTR, находящегося в “теневом” регистре.
- По адресу локальной таблицы дескрипторов, находящемуся в ее дескрипторе, и номеру дескриптора из обрабатываемого селектора находим дескриптор сегмента в локальной таблице дескрипторов.
- Записываем дескриптор сегмента в “теневой” регистр сегментного регистра микропроцессора для ускорения последующих обращений к искомому сегменту.
Таким образом, при обращении к сегменту через таблицу LDT появляется дополнительный уровень вложенности, снижающий быстродействие микропроцессора. “Теневые” регистры микропроцессора частично обеспечивают решение этой проблемы.
Поле адреса дескриптора, полученного из локальной или глобальной таблицы дескрипторов, определяет начало искомого сегмента. При суммировании полученного базового адреса сегмента и смещения в сегменте получается линейный адрес искомой ячейки памяти.
В случае если режим страничной адресации выключен (в регистре CR0 бит PG = 0), полученный линейный адрес равен физическому адресу искомого операнда или команды.
Рассмотрим подробнее процесс получения адреса операнда на примере команды
MOV EAX, [ECX+ESI+20h].
В этой команде нет специальных указаний об использовании сегмента, поэтому она обращается к текущему сегменту данных, селектор которого по умолчанию находится в сегментном регистре DS. Пусть (DS) = 0000000000011.0.XXb.
Формирование физического адреса операнда включает следующие действия (для сегментированного ЛАП):
- Образовать эффективный адрес (вычислить смещение в сегменте):
EA = (ECX)+(ESI)+20h.
- Выбрать 3-й дескриптор ( Index = 3 ) из GDT (TI = 0).
Для этого:
- Получить линейный адрес: , где
 -базовый адрес сегмента из считанного дескриптора с номером 3.
-базовый адрес сегмента из считанного дескриптора с номером 3. - Так как при сегментной организации адресного пространства линейный адрес равен физическому, следует обратиться к памяти по сформированному адресу и передать двойное слово в EAX.
При TI = 1 потребовалось бы еще одно обращение к памяти для счтывания дескриптора LDT из GDT.
Чтобы сократить число обращений к памяти (а такой процесс должен проходить и при считывании кода каждой команды), в микропроцессорах с архитектурой IA-32 применяется так называемое кэширование дескрипторов. Кэширование опирается на тот факт, что обращение к памяти производятся гораздо чаще, чем изменение используемых сегментов и переключение задач. Поэтому с каждым регистром, содержащим селекторы тех или иных сегментов (сегментные регистры, а также регистры локальной таблицы дескрипторов LDTR и регистр задач TR ), ассоциируются “теневые”, или кэш-регистры.
При первом считывании дескриптора, определяемого данным селектором, процессор автоматически считывает (кэширует) нужный дескриптор в соответствующий “теневой” регистр. Поскольку теперь дескриптор находится внутри МП, для получения линейного адреса памяти потребуется только сформировать эффективный адрес и просуммировать его с базовым адресом сегмента из нужного “теневого” регистра.
Так как программа обычно редко модифицирует регистры с селекторами, в защищенном режиме она будет выполняться примерно с такой же скоростью, как и в реальном режиме.
Помимо локальной и глобальной таблиц дескрипторов в микропроцессорной системе используется также дескрипторная таблица прерываний ( IDT ). Она содержит дескрипторы специальных системных объектов, которые определяют точки входа в процедуры обработки прерываний.
IDT служит заменой таблицы векторов прерываний 16-разрядного микропроцессора. Обращение к ней проводится только аппаратными средствами МП при возникновении аппаратных прерываний или особых случаев при выполнении программы. Программы самостоятельно не могут обратиться к IDT, так как единственный бит индикатора таблицы в селекторе сегмента идентифицирует только GDT или LDT.
До перевода процессора в защищенный режим необходимо создать таблицы GDT и IDT и соответственно инициализировать регистры GDTR и IDT R. Таблицы GDT и IDT определяются при загрузке в соответствующие регистры GDTR и IDT R базового адреса и предела. Это действие осуществляется только один раз в ходе подготовки к переходу в защищенный режим, и в дальнейшем содержимое GDTR и IDTR не изменяется. Это значит, что местонахождение таблиц GDT и IDT в известном смысле фиксировано, и они не могут участвовать в свопинге.
Источник
Выше было показано, что процессор i486 поддерживает три типа дескрипторных таблиц: общесистемные таблицы GDT и IDT, a также таблицы LDT. Последние таблицы при необходимости создаются по одной для каждой задачи и служат расщирением таблицы GDT при реализации мультизадачных систем. Наличие таблицы LDT увеличивает адресное пространство задачи, которое недоступно для других задач. Если задача не имеет таблицы LDT,что вполне допустимо, все требующиеся ей дескрипторы берутся из таблицы GDT; при этом необходимо избегать загрузки в сегментные регистры селекторов с битом TI = 1. Таким образом, с помощью таблиц LDT можно разрешить доступ к критическим областям памяти, например видеобуферу или дисковому контроллеру, только отдельным задачам.
Базовая структура адресного пространства с таблицами GDT и LDT предполагает, что каждая задача имеет свою таблицу LDT и все задачи пользуются общей таблицей GDT. В результате сегмент доступен либо только одной задаче, либо всем задачам. Для небольших однопользовательских систем характерно отсутствие таблиц LDT. Наконец, группа взаимосвязанных задач (образующих задание) может использовать одну и ту же таблицу LDT. Все задачи в группе разделяют одно адресное пространство, но группа, как целое, обладает своими сегментами, изолированными от остальной части системы. Более сложные структуры разделения адресного пространства реализуются с помощью альтернативного именования сегментов.
Локальная дескрипторная таблица, так же как таблица GDT, представляет собой массив 8-байтных дескрипторов сегментов. В любой момент времени процессор работает только с одной таблицей LDT, а при переключении задачи изменяется и активная таблица LDT. Поэтому для локализации таблицы LDT вместо 48-битного регистра, аналогичного регистрам GDTR и IDTR, в процессоре i486 имеется 16-битный регистр LDTR, содержащий только селектор LDT. Этот селектор выбирает в таблице GDT специальный дескриптор, который описывает текущую таблицу LDT, т.е. определяет ее базовый адрес и предел. Таким образом, при обращении к сегменту данных, который определяется селектором с битом TI = 1, появляется дополнительный уровень косвенности. Отметим, что в таблице LDT не могут находиться дескрипторы LDT, т.е. процессор не допускает дальнейшего «вложения косвенности».
Дескриптор LDT, формат которого показан на рис.2.10, является первым примером системных дескрипторов сегментов с битом S = 0. Такие дескрипторы не имеют бита обращения А и за счет этого поле типа расширено до четырех бит. Для дескриптора LDT поле типа содержит 2 (0010В). В поле базового адреса находится базовый адрес таблицы LDT, а в поле предела — предел сегмента таблицы LDT. Для задания предела можно использовать все 20 бит; функционирует также бит гранулярности G, поэтому можно создать таблицу LDT с размером больше 64 Кбайт, но на практике этого не требуется.
также не присутствуют. Процессор даже не разрешает загрузить регистр LDTR селектор неприсутствующей
таблицы LDT.
Отметим, что дескриптор LDT, как и любой другой дескриптор сегмента, имеет бит присутствия Р. Если дескриптор LDT отмечен неприсутствующим (Р = 0), считается, что все дескрипторы из LDT
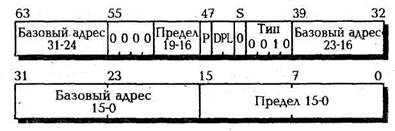
Рис.2.10. Формат дескриптора таблицы LDT
Чтобы начать пользоваться таблицей LDT, нужно просто поместить в регистр LDTR селектор нужной таблицы. В этом отношении регистр LDTR действует как и любой другой сегментный регистр. Для сокращения числа обращений к памяти у регистра LDTR предусмотрен теневой регистр (он показан пунктиром на рис. 2.6), в который процессор автоматически считывает дескриптор LDT при загрузке селектора в регистр LDTR.
При попытке загрузить в регистр LDTR что-то отличающееся от селектора, выбирающего дескриптор LDT, процессор формирует общее нарушение защиты и «виноватый» селектор включается в стек как код ошибки. Когда в дескрипторе бит Р = 0, генерируется особый случай неприсутствия, а селектор по-прежнему будет служить кодом ошибки. Загрузка в регистр LDTR пустого селектора (значения 0000Н — 0003Н) допускается; такая операция сообщает процессору о том, что задача не будет пользоваться локальной дескрипторной таблицей.
Мы пока не касаемся дескрипторной таблицы прерываний IDT. Связано это с тем, что программам никогда не разрешается прямое обращение к IDT. Именно поэтому в селекторе достаточно одного бита индикатора таблицы TI. Таблицу IDT процессор i486 использует автоматически при обработке аппаратных и программных прерываний, которым посвящена следующая лекция.
2.1.7. Особенности сегментации
Процессор i486 разрешает создание сегментов, в которых допускаются операции только считывания, только исполнения, считывания/записи и исполнения/считывания. Однако в нем невозможно прямо создать характерные для процессора 8086 сегменты, в которых одновременно разрешены операции считывания, записи и исполнения. Тем не менее, образовать такие сегменты можно другими средствами.
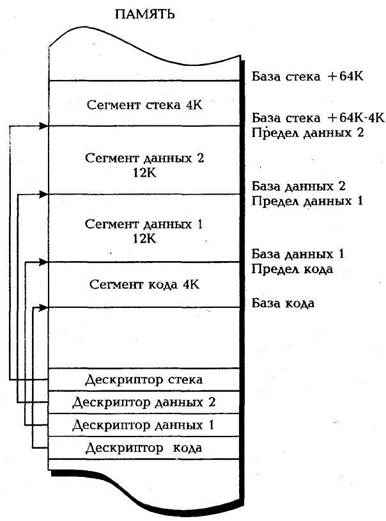
Рис.2.11. Неперекрывающиеся сегменты памяти
В способе сегментации памяти процессора 8086 нет никаких трудностей для обращения по одному и тому же физическому адресу с привлечением различных сегментных регистров. Если, например, в регистрах DS и ES содержатся одинаковые начальные адреса, то оба регистра определяют один и тот же сегмент. Кроме того, как отмечалось выше, множество пар сегмент:смещение могут определять один и тот же физический адрес. Аналогичную ситуацию в процессоре i486 можно смоделировать путем тщательного подбора дескрипторов сегментов.
Обычно дескрипторы сегментов создаются во время инициализации системы для определения всех используемых областей памяти с учетом их назначения. Например, можно определить один сегмент кода для хранения машинных команд (т.е. собственно программы), один или два сегмента для данных и один сегмент для стека, рассчитанный на максимальный размер стекового кадра. Обычно эти сегменты должны занимать различные области памяти. При желании сегментам можно назначить соседние адреса так, чтобы конец одного сегмента совпадал с началом другого. На рис. 2.11 показаны неперекрывающиеся (непересекающиеся) сег мент кода 6 Кбайт, два сегмента данных по 12 Кбайт и сегмент стека 4 Кбайт.
Представим теперь, что дескриптор первого сегмента данных изменен с целью увеличения его предела на 4 Кбайт. В этом случае два сегмента данных оказываются перекрывающимися, что показано на рис. 2.12. Такое перекрытие вполне допустимо, так как процессор i486 не накладывает никаких ограничений на определения перекрывающихся сегментов.
Перекрытие двух или более сегментов в некоторых отношениях может оказаться благоприятным. К любой ячейке в области перекрытия можно обращаться несколькими способами. Например, считывание по смещению 0 из сегмента данных 2 эквивалентно считыванию по смещению 3000Н из сегмента данных 1.
Выше говорилось, что процессор запрещает запись в сегменты, которые определены как исполняемые. Но не будет ошибкой запись в сегмент, который определен с разрешенной операцией записи и просто перекрывает то же линейное адресное пространство, что и исполняемый сегмент. Если дескрипторы сегмента кода и сегмента данных имеют одинаковые базовые адреса и пределы, то можно будет «модифицировать код» и «выполнять данные». Такой прием создания нескольких дескрипторов одного и того же адресного пространства называется альтернативным именованием (aliasing). Очевидно, дескрипторы можно считать именами сегментов; тогда несколько дескрипторов одного и того же сегмента (т.е. альтернативные имена) естественно назвать псевдонимами.
В предельной ситуации можно определить сегмент данных с разрешенными операциями записи и считывания, который имеет базовый адрес 0 и предел OFFFFFFFFH. Загрузка селектора такого дескриптора в сегментный регистр позволяет считывать и записывать по любому адресу всего линейного адресного пространства процессора i486. По существу, для любого сегмента в системе имеется альтернативное имя. Конечно, система не обязательно должна иметь физическую память 4 Гбайт; этот пример только показывает,
о попускается описывать несуществующее пространство памяти к же легко, как и перекрывающиеся диапазоны адресов.
ПАМЯТЬ
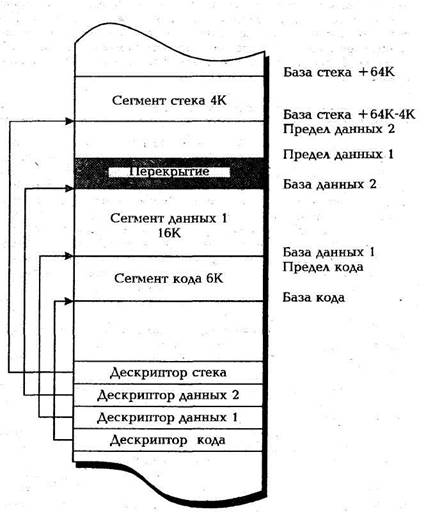
Рис.2.12. Перекрывающиеся сегменты памяти
Перекрытие и альтернативное именование оказываются очень удобными для разделения данных между задачами. Например, создание для сегмента кода псевдонима в виде сегмента данных позволяет разработать самомодифицирующиеся программы. Упомянем еще один очень важный момент. Пространство, занятое дескрипторной таблицей, невозможно адресовать, не имея определяющего его дескриптора. Если не создать псевдонимов для дескрипторных таблиц в виде сегментов данных до перевода процессора i486 в Р-режим, то к таблицам будет невозможно обратиться. Конечно, определения этих сегментов должны быть максимально защищенными, так как разрешение всем программам доступа к таблицам GDT, IDT и LDT для считывания и записи приведет к катастрофическим последствиям.
Источник